


Is Gemini Deep Research A ChatGPT Deep Research Challenger?
Exploring AI Models for Fun and Insight

As I mentioned last week, I’ve been spending more time testing various AI models. Every new technology follows a hype cycle. AI is no exception. One major challenge users will face in the coming years is keeping their knowledge current about which model excels in particular tasks. Everything is moving fast.
My top AI fun tip for the week is to try out Gemini Deep Research from Google. If you’ve only explored free AI offerings or haven’t experimented with open-source models on your own hardware, you’re not experiencing the cutting edge. Thankfully, it's now easy for anyone, technical or otherwise, to try AI models through intuitive chat-based interfaces. Fortunately, Gemini Deep Research is free for now.
The last decade of product development has all combined to make the tools being built now fantastic as this is pretty accessible even to non-technical folks. You don’t need to become a developer and generate an API key unless you really want to go down that path with vibe coding from Cursor or Windsurf.
One “easy” path is to pay for Perplexity Pro and then run the same query through each different model to judge the difference in output.
You can also select which implementation of Perplexity that you want to try out. In my opinion so far, ChatGPT Deep Research is still the best performer in this category, much better than Perplexity or Grok 3. The other method is just signing up for each service individual, like Qwen Chat. They recently released an updated model so I used that as a base to generate some sample output to compare across different tools.
Comparative Insights: Qwen, Deepseek, and ChatGPT

I like how so many of the models “expose” their thinking, even if it is obscured for model security reasons. You can see from Qwen’s output below, it’s very high level without initially providing a very detailed prompt with example output structure.

If you try the same query in Deepseek with the DeepThink R1 setting it displays its thinking in the same manner:
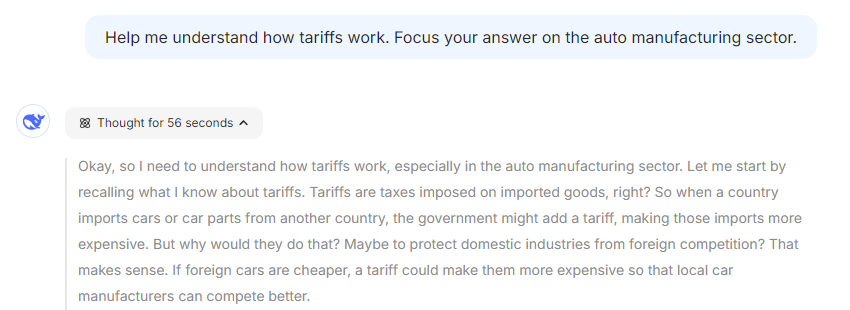
Similar to QwenChat2.5, the output is quite high level, again without requesting detailed structured output in the prompt. ChatGPT o1 Pro choose to display its thinking a bit differently:
The output is high level yet shows a bit more “reasoning” ability, as you might expect.

If I try again with the ChatGPT 4.5 research preview with Deep Research enabled, the report produced is pretty solid.

I read a lot of content every day - news, tweets, substack, RSS feeds, PDFs - whatever. Each time I come across a word, concept or wider topic I want to learn a bit more about I’m firing off a Deep Research query and looking forward to what comes back. A fun thing to do is take an opinion piece you think is hopeless and ask Deep Research to “fact check this”.
After doing that consistently for the past few weeks, I’ve found the report outputs much more fun than going down Wikipedia rabbit holes and old websites with scanned PDF documents.
Do you remember Wikipedia? It used to be a thing. I would say as a previous Wikipedia enjoyer, I am now almost exclusively choosing Deep Research reports as a the “first attempt” at investigating something new or summarising an area I’m interested in learning a bit more about.
Of course - you still need to double check concepts and facts and figures. Being able to chat using text or voice really is great as a reading and learning companion.
My Surprise of the Week: Google Gemini Deep Research
My main surprise of the week in AI fun was the performance of Google Gemini Deep Research. It cleanly presents its research plan and it seems to search a much wider number of sources relevant to the query. You can edit the query before it proceeds.
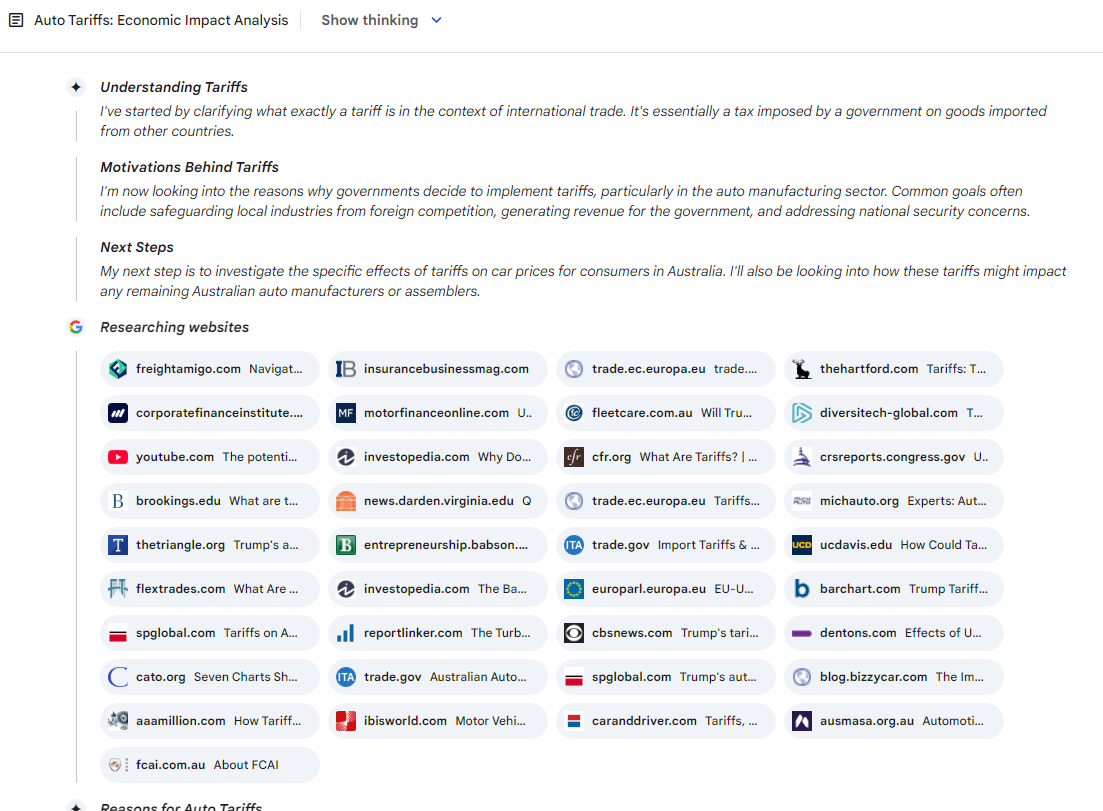
And Gemini Deep Research generates a clear and comprehensive output for the query. I am impressed. For the next week I’ll try sending more queries here to see what the output is like - it is definitely the only challenger to ChatGPT Deep Research at the moment given Grok 3’s limitations. Unfortunately there seem to be quite a few “AI safety” guardrails in place which reduce the scope of testing possible.

I’m not going to be building a 3D game anytime soon - I’m going to keep having fun with trying out all of these tools.
Over at Global Custody Pro this week I wrote about the crypto credibility gap and have had some interesting feedback from readers on the challenges of regulated institutions moving into the digital asset space more.
Until next week,
Brennan